تشخیص گوینده
1507. بررسی و ارزیابی چند روش تشخیص جنسیت گوینده از روی گفتار
مقاله شبیه سازی شده کد پروژه:1507 موضوع:پردازش گفتار بررسی و ارزیابی چند روش تشخیص جنسیت گوینده از روی گفتار شامل:مقاله اصلی +گزارش کاملی از ده مقاله در این مورد و شبیه سازی با متلبMatlab عنوان مقالات: 1-A Comparative Study of Gender and Age Classification in Speech Signals 2-Age and Gender Classification using Fusion of Acoustic and Prosodic Features 3-Age and Gender Recognition from Speech Patterns Based on Supervised Non-Negative Matrix Factorization 4-Age and Gender Classification using Fusion of Acoustic and Prosodic Features 5-Combining Five Acoustic Level Modeling Methods for Automatic Speaker Age and Gender Recognition 6-COMPARISON OF FOUR APPROACHES TO AGE AND GENDER RECOGNITION FOR TELEPHONE APPLICATIONS 7-تشخيص جنسيت به كمك شبكه عصبي mpl و شبکه عصبی ژنتیک و شبکه anfis 8-Genderr ecognitionfr oms peechP. art I: Coarsea nalysis 9-تشخيص جنسيت گوينده صدا با استفاده از فرآيندهاي تصادفي چکیده: مطالعات پزشکی نشان می دهد که دستگاه صوتی آقایان بزرگتر از خانم هاست و از آنجایی که بسیاری از ویژگی های صوتی ناشی از اندازه و شکل اندام گویایی است پس این تفاوت مطمئنا باید (حداقل) در یک ویژگی صوتی تاثیر بگذارد. یکی از این تاثیرها روی تفاوت فرکانسی است. فرکانس گفتار خانم و آقا یکسان نیست؛ فرکانس خانمها بالاتر و در محدوده 250-450هرتز و آقایان پایین تر و در محدوده 50-250 است. بنابراین اگر فرکانس پایه گفتار را در صوت تشخیص بدهیم بنابر محدوده فرکانسی گفتار قادر به تشخیص جنسیت گوینده هستیم که با روشهای مختلفی می توان این فرکانس پایه را بدست آورد. هم چنین در این مقاله از روش های دیگری نظیر انواع شبکه های عصبی و استفاده از انرژی جنبشی صوت و مخزوط گوسی نیز بررسی شده و همینطور ترکیب چند روش در کنارهم برای بهبود کارآیی و دقت و سرعت سیستم مطرح شده است. کلمات کلیدی: تشخیص جنسیت ؛ فرکانس پایه ؛ مدل مخلوط گاوسی ؛ شبكه عصبي MLP؛ شبكه عصبي ANFIS؛ ضرایب MFCC؛ ضرایب LPCC سفارش پروژه
ترجمه مقاله تعیین هویت گوینده مستقل از متن، توسط مدل های مخلوط گاوس

عنوان انگلیسی مقاله: Efficient Text-Independent Speaker Verification with Structural Gaussian Mixture Models and Neural Networkعنوان فارسی مقاله: تعیین هویت گوینده مستقل از متن، توسط مدل های مخلوط گاوس ساختاری و شبکه های عصبیدسته: کامپیوتر و فناوری اطلاعاتفرمت فایل ترجمه شده: WORD (قابل ویرایش)تعداد صفحات فایل ترجمه شده: 26لینک دریافت رایگان نسخه انگلیسی مقاله: دانلودترجمه ی سلیس و روان مقاله آماده ی خرید می باشد._______________________________________چکیده ترجمه:چکیده – ما سیستم یکپارچه ای را در ارتباط با مدل های مخلوط گاوس ساختاری (SGMM) و شبکه های عصبی به منظور دستیابی به راندمان محاسباتی و دقت بالا در ارتباط با تعیین هویت گوینده ارائه می دهیم. مدل پس زمینه ساختاری (SBM) در ابتدا از طریق خوشه بندی زنجیره ای تمام موئلفه های مخلوط گاوس در ارتباط با مدل پس زمینه ساختاری ایجاد می گردد. به این ترتیب، یک فضای اکوستیک به بخش های چندگانه ای در سطوح مختلف قدرت تشخیص، جزء بندی می گردد. برای هر یک از گوینده های مورد نظر، مدل مدل مخلوط گاوس ساختاری (SGMM) از طریق استدلال حداکثری (MAP) سازگار با مدل پس زمینه ساختاری (SBM) ایجاد می گردد. در هنگام تست، تنها زیرمجموعه کمی از موئلفه های مخلوط گاوس برای هر بردار مختصات محاسبه می گردد تا هزینه محاسبه را به طور قابل توجهی کاهش دهد. علاوه بر این، امتیازات حاصل شده در لایه های مدل های درخت ساختار، برای تصمیم گیری نهایی از طریق شبکه عصبی ادغام می گردند. وضعیت های مختلفی در بررسی های انجام شده بر روی داده های حاصل از گفتگوهای تلفنی مورد استفاده در ارزیابی هویت گوینده NIST ، مقایسه شد. نتایج تجربی نشان می دهد که کاهش محاسبه توسط فاکتور 17 از طریق 5% کاهش نسبی در میزان خطای هم ارز (EER) در مقایسه با خطو مبنا، حاصل می گردد. روش SGMM-SBM (مدل مخلوط گاوس ساختاری- مدل پس زمینه ساختاری)، مزایایی را نسبت به مدل اخیرا مطرح شده GMM (مدل مخلوط گاوس) داشته، که شامل سرعت بالاتر و عملکرد تشخیص بهتر، می باشد.کلیداژه: خوشه بندی گاوس، شبکه عصبی، تعیین هویت گوینده، مدل مخلوط گاوس ساختاری1. مقدمهتحقیقات بر روی تشخیص گوینده که شامل تعیین هویت و تطبیق موارد می باشد به عنوان یک مورد فعال برای چندین دهه به شمار آورده می شود. هدف این می باشد تا تجهیزانت داشته باشیم که به صورت اتوماتیک فرد خاصی را تعیین هویت کرده یا فرد را از طریق صدای او تشخیص دهیم. بنابر روش های زیست سنجی، تشخیص صدای افراد می تواند در بسیاری از موارد همانند، شبکه های امنیتی، تراکنش های تلفنی و دسترسی به بخش ها کاربرد داشته باشد. گوینده ها به دو گروه تقسیم می شوند.گوینده های هدفمند و گوینده های ...
دانلود کد تشخیص گوینده در متلب
برنامه Open source تشخیص گوینده در نرم افزار متلب : برای دانلود کلیک کنید ... اعمال جبر در سمبلیک+ انتگرال گیری و مشتق گیری سمبلیک + استاندارد سازی و ساده سازی عبارات سمبلیک + تابع collect + تابع factor + تابع expand + محاسبه سمبلیک تبدیل لاپلاس + عکس لاپلاس + محاسبه سمبلیک تبدیل z در متلب + عکس تبدیل z + حل معادلات جبری + حل معادلات دیفرانسیل به روش سمبلیک + آشنایی با پنجره های MATLAB + مقدمات کار با MATLAB + محاسبات عددی آرایه ها + آرایه های استاندارد + اندازه ماتریس ها + ایجاد تغییر در ماتریس ها + مرتب آردن آرایه ها + جستجو در آرایه ها + کاربرد در داده های آماری + ماتریس به عنوان ضرایب چند جمله ای + ماتریس به عنوان مجموعه + محاسبات ماتریسی + مدیریت فایل ها و متغیرها + تابع plot + بر چسب ها، تنظیمات و ... + نمودارهای متعدد + ساخت function file + حلقه های تکرار + حلقه for + حلقه while + عملگرهای منطقی + شرط If - Else – End + شرط Switch-Case + توقف روند اجرای برنامه + MATLAB چیست؟ + استفاده از help + استفاده ازdemo + عملیات ابتدایی در مطلب+ تعریف کردن آرایه ها و عملیات جبری روی آنها + ذخیره کردن و بازیابی داده ها + عملیات ماتریسی روی آرایه ها + عملیات عضو به عضو روی آرایه ها + تنظیم خروجیها روی صفحه نمایش با دستورات format و disp + چند جمله ایها + ریشه های یک چند جمله ای + محاسبه
سیگنال
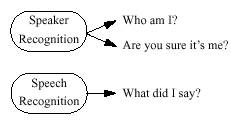
۱- اهمیت مدلسازی سیگنال تشخیص کامپیوتری صحبت در واقع بر دارندهی دو نوع عمل اصلی تشخیص است: تشخیص صحبت و تشخیص گوینده. با تحلیل یک موج صوتی میتوان خصیصههای۱ اندامهای گفتاری گوینده را تخمین زد که این خصیصهها راهکاری برای تشخیص هویت و تصدیق آن به روش زیستسنجی فراهم میآورند. در مقابل، سیستمهای تشخیص صحبت برای درک مفهوم موج صوتی گفته شده تلاش میکنند. جهت بیشتر تحقیقات فعلی در فنآوری تشخیص صحبت به سمت ایجاد سیستمهای مستقل از گوینده است که توانایی تبدیل صحبت همهی گویندگان را داشته باشد. در حالی که اهداف این دو نوع سیستم کاملاً متفاوت به نظر میرسند هر دو عمیقاً از آبشخوری به نام الگوریتمهای پردازش سیگنال برای استخراج خصیصهها۲ تغذیه میشوند. در هر دو زمینه تلاش برای پیدا کردن دستهای از خصیصهها که در مقابل تغییرات محیطی پایدار باشند ادامه دارد. این قسمت مروری خواهد داشت بر الگوریتمهای استخراج خصیصهها که در هر دو زمینه استفاده شدهاند و شامل ارزیابی کوتاهی از الگوریتمهای گوناگون مدلسازی سیگنال با آزمایشهای تشخیصی کوچک میباشد. ۲- آشنایی با مدلسازی سیگنال هدف سیستمهای تشخیص گوینده بازشناسی خصیصههای اندامهای گفتاری و حالت صحبت کردن با استفاده از صدای گوینده به منظور اهداف تشخیص هویتی میباشد. ساختار اندامهای صوتی، اندازهی چالهی بینی و ویژگیهای تارهای صوتی همگی با استفاده از تحلیل سیگنال قابل تخمین هستند. تشخیص گوینده اصطلاحی کلی است که به اعمال تشخیص هویت گوینده و تأیید هویت گوینده اطلاق میگردد. برای تشخیص، خصیصههای تخمینی گوینده با خصیصههای موجود در یک پایگاه دادهها از کاربران ثبت شده برای یافتن نزدیکترین خصیصههای قابل تطبیق مقایسه میشوند. برای تأیید هویت، ادعای هویتی گوینده بر اساس امضای زیستسنجی وی پذیرفته میشود و یا رد میگردد. شکل شماره ۱ – وظایف مختلف تشخیص صحبت تلاش دارد تا یک سیگنال صوتی صحبت را به واژهها تبدیل کند. انسانها واژهها را با حرکت دادن اندامهای صوتی به یک سری از مکانهای قابل پیشبینی ادا میکنند. اگر این دنبالهها از سیگنال استخراج گردند واژههای گفته شده میتوانند تشخیص داده شوند. بسیاری از کاربردهای تشخیص صحبت نیازمند سیستمهای مستقل از گوینده میباشند این تولیدات میتوانند صحبت هر گویندهای را تشخیص دهند. اگر چه این دو هدف کاملاً متفاوت به نظر میرسند هر دوی آنها بر روی دادههای صحبت تشخیص الگو را اعمال میکنند. بعضی از سیستمهای موجود مانند Nuance ۶ server هم تشخیص صحبت و هم تأیید هویت گوینده را به صورت همزمان اعمال ...
مروری بر سیستم تشخیص گفتار و کاربرد آن
چكيده: سيستم تشخیص گفتار نوعی فناوری است که به یک رايانه این امکان را می دهد که گفتار و کلمات گوینده را بازشناسی و خروجي آنرا به قالب مورد نظر، مانند "متن"، ارائه كند. در این مقاله پس از معرفی و ذكر تاريخچهاي ازفناوري سیستم ها تشخيص گفتار، دو نوع تقسیم بندی از سيستمها ارائه می شود، و سپس به برخی ضعف ها و نهایتاً کاربرد این فناوری اشاره می شود. كليد واژه ها: سيستمهاي تشخیص گفتار، فناوري اطلاعات، بازشناسي گفتار 1. مقدمهگفتار برای بشر طبیعی ترین و کارآمدترین ابزار مبادله اطلاعات است. کنترل محیط و ارتباط با ماشین بوسیله گفتار از آرزوهای او بوده است.طراحی و تولید سیستم های تشخیص گفتار هدف تحقیقاتی مراکز بسیاری در نیم قرن اخیر بوده است.یکی از اهداف انسانها در تولید چنین سیستم هایی مسلماً توجه به این نکته بوده است که "ورود اطلاعات به صورت صوتی ،اجرای دستورات علاوه بر صرفه جویی در وقت و هزینه ،به طرق مختلف کیفیت زندگی ما را افزایش می دهند.امروزه دامنه ای از نرم افزارها (که تحت عنوانSpeech Recognition Systems معرفی می شوند) وجود دارند که این امکان را برای ما فراهم کرده اند.با استفاده از این تکنولوژی می توانیم امیدوار باشیم که چالش های ارتباطی خود را با محیط پیرامون به حداقل برسانیم.2.تعریف قبل از پرداختن به به سیستم های تشخیص گفتار لازم است که فناوری تولید گفتار و تشخیص گفتار با تعریفی ساده از هم متمایز شوند: ● فناوری تولید گفتار(Text To Speech):تبدیل اطلاعاتی مثل متن یا سایر کدهای رایانه ای به گفتاراست.مثل ماشین های متن خوان برای نابینایان،سیستم های پیغام رسانی عمومی. سیستم های تولید گفتار به خاطر سادگی ساختارشان زودتر ابداع شدند. این نوع از فناوری پردازش گفتار موضوع مورد بحث در این مقاله نیستند. ● فناوری تشخیص گفتار(Speech Recognition System ): نوعی فناوری است که به یک کامپیوتراین امکان را می دهد که گفتارو کلمات گوینده ای را که از طریق میکروفن یا پشت گوشی تلفن صحبت می کند،بازشناسی نماید. به عبارت دیگر در این فناوری هدف خلق ماشینی است که گفتار را به عنوان ورودی دریافت کند و آنرا به اطلاعات مورد نیاز (مثل متن)تبدیل کند. 3.تاریخچه فناوری تشخیص گفتاراولین سیستم های مبتنی بر فناوری تشخیص گفتار در سال 1952 در"آزمایشگاههای بل"طراحی شد.این سیستم به شیوه گفتار گسسته و به صورت وابسته به گوینده و با تعداد لغت محدود 10 لغت عمل می کرد.در اوایل دهه 80 میلادی برای اولین بار الگوریتم مدلهای مخفی مارکوف "Hidden Markov Model" ارائه شد.این الگوریتم گامی مهم در طراحی سیستم های مبتنی بر گفتار پیوسته به حساب می آمد.همچنین در طراحی این سیستم از مدل شبکه عصبی ...
نرمافزار تشخیص گفتار فارسی به بازار میآید
نرمافزار تشخیص گفتار فارسی به بازار میآید<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" /> آیا با پیشرفت فناوریهای نوین بالاخره زمانی خواهد رسید که دیگر نیازی به تایپ کردن با نوشتن متن نباشد و تنها با خواندن متن، بتوان آن را تایپ کرد؟ بهنظر میآید که چنین پیشرفتی در آینده نزدیک محقق خواهد شد. امروزه نرمافزارهای تشخیص فرمانهای صوتی به صورتی محدود در انواع کامپیوترها و بهخصوص روی گوشیهای موبایل نصب شده است. با کمک این تکنولوژی ارتباط انسان با کامپیوتر بسیار راحتتر و سریعتر شدهاست و بهزودی آرزوی بشر در برقراری ارتباط گفتاری با ماشینها تحقق خواهد یافت. تایپ کامپیوتری هم از جمله کارهای متداول و وقتگیر برای کاربرهای عادی و پیشرفته کامپیوتر است؛ به ویژه که این مسئله برای کاربرانی که به هر دلیل مایل به استفاده از صفحه کلید نیستند، کاری خستهکننده است و استفاده از قابلیت تشخیص خودکار گفتار توسط کامپیوتر باعث سهولت و صرفهجویی در زمان تایپ میشود. تلاش گروههای تحقیقاتی و شرکتهای خارجی برای دستیابی به تکنولوژی تشخیص گفتار به عنوان یکی از تکنولوژیهای سطح اول دنیا، به چندین دهه میرسد، ولی به دلیل پیچیدگی موجود در گفتار انسان هنوز رسیدن به دقت صددرصد امکانپذیر نشده است. نخستین نرمافزار فارسی در کشورمان نیز فعالیتهایی در زمینه طراحی و ساخت نرمافزارهای تشخیص گفتار به زبان فارسی آغاز شدهاست. در این راستا گروهی از فارغالتحصیلان دانشگاه صنعتی شریف از سال 82 اقدام به تهیه موتور تشخیص گفتار پیوسته فارسی کردهاند. برای بالا بردن دقت این نرمافزار در تشخیص گفتار فارسی، از مدلهای آماری و همچنین مدلهای دستوری زبان استفاده شده است. ارایی این سامانه که «نویسا» نام دارد، در شرایط آزمایشگاهی و محیط آرام و بدون نویز قابل قبول است، اما زمانی که از آن در عمل و در شرایط عادی مانند داخل اداره، استفاده میشود، کارایی سامانه افت شدیدی دارد. برای جبران این مسئله از راهحلهایی جهت مقاومسازی سامانه به تغییرات موجود در شرایط آکوستیکی محیط و تغییرات موجود بین گویندههای مختلف استفاده شده است، به گونهای که سامانه موجود که مستقل از گوینده و با واژگان بزرگ است، با بهرهگیری از بهترین روشهای مقاومسازی میتواند خود را با شرایط محیطی جدید و صدای گوینده تطبیق دهد. این مسئله سامانه جاری را به نمونهای موفق و کاربردی در مقایسه با انواع خارجی مشابه کرده است. بهاین ترتیب، نسخه جاری این سامانه دارای دقت تشخیص 95درصد در محیط اداری، قابلیت استفاده در همه ویرایشگرها یا ...
لب خوانی چیست؟
مقدمهمشاهده گوینده نه تنها درک گفتار شنیده شده را در حضور نویز بهبود می بخشد بلکه حتی می تواند چگونگی درک یک صدا را نیز متاثر کند.لب خوانی می تواند نقشی اساسی در بهبود ارتباطات ،افزایش استفاده از سمعک ودیگر وسایل تقویتی داشته و ابزاری هماهنگ کننده در زندگی روزمره در خانواده و اجتماع به حساب آید.هرچه میزان آسیب شنوایی بیشتر باشد ،فرد بیشتر متکی به اطلاعات بینایی برای برقراری ارتباط می شود. فرد آسیب دیده شنوایی به طور ذاتی دارای این توانایی است که نقص خود را در مورد اطلاعات شنیداری با لب خوانی جبران کندلب خوانی چیست؟پروسه ای است شبیه خواندن که طی آن فرد از طریق سیگنال های بینایی ارتباط برقرار می کند.لب خوانی 2مرحله دارد:1)فرد یاد بگیرد که چگونه توالی الگو های بینایی را به ذهن بسپارد.2)درک پیام.لازمه ی درک پیام داشتن زبان واحد میان گوینده و لب خوان است.آموزش لب خوانی در بزرگ سالانی که زبان پایداری قبل از آسیب شنوایی داشته اند به مراتب راحت تر از کودکانی است که هیچ ذخیره ی زبانی ندارند.مسلما می توان مهارت های لب خوانی را با آموزش و تمرین بهبود بخشید.اما تفاوت های فردی علی رغم آموزش نیز وجود دارد. چه کسی لب خوان بهتری است؟تحقیقات خیلی زیاد نشان داد ه که پیش بینی چگونگی اجرای لب خوانی ،مشکل است.اجرا لب خوانی را نمی توان توسط عواملی چون :هوش فرد، موفقیت آموزشی (تحصیلات)، مدت زمان نا شنوایی، سن شروع آسیب شنوایی، پیش بینی نمود.تعدادی از متغییر ها تا اندازه ای می تواند قابل پیش بینی باشد،برای مثال به طور متوسط زنان نسبت به مردان لب خوان بهتری هستند.مردم در لب خوانی کردن هایشان بسیار متفاوت هستنداگر فردی از پشت پنجره بسته با شما صحبت کند ،شما می توانید اورا ببینید اما نمی توانید صدای اورا بشنوید،در چنین حالتی شما کمتر از 20درصد کلمات گفته شده را تشخیص خواهید داد.در مواردی که هم چهره ی شخص گوینده و هم سیگنال گفتاری وی را دریافت کنیم اطلاعات بیشتری از مکالمه در اختیار ما قرار می گیرد.چرا لب خوانی کردن اینقدر مشکل است؟پاسخ این سوال مربوط می شود به عواملی چون:- قابلیت رؤیت اصوات- سرعت گفتار- آموزش- زاویه ی دید- تاثیرات Coarticulation واسترس- تاثیرات گویندهVisemes & Homophenous- قابلیت رؤیت اصواتدر بسیاری از اصوات حرکات دهان که قابل مشاهده است اندک می باشد کلماتی که روی چهره و دهان بیشتر قابل مشاهده هستند،اغلب با همخوان هایی ایجاد می شوند که با بسته شدن لب هاتولید می شوند مانند// p.b.m ویا همخوان هایی که با فشار دادن دندان های جلویی فک بالا بر لب پایین تولید می شوند مانند/f.v/ ویا اینکه نوک زبان به دندان های جلویی فک بالا تماس ...
نرم افزار تایپ گفتار فارسی طراحی شد

در پی دستیابی متخصصان یک شرکت دانش بنیان ایرانی به فن آوری پیشرفته طراحی و ساخت نرم افزار تشخیص گفتار پیوسته فارسی و امکان تایپ مستقیم گفتار توسط رایانه ، نسخه جدید این نرم افزار با قابلیت های قرائت متون مختلف و تشخیص خودکار گوینده طراحی شد. به گزارش ایسنا، دکتر هادی ویسی، مدیرعامل شرکت سازنده این نرم افزار گفت: در نسخه جدید نرم افزار تایپ گفتار فارسی (نویسا) چهار قابلیت جدید به کاربران عرضه شده است. این نرم افزار علاوه بر تایپ سریع متون همزمان با گفتار گوینده، قابلیت تبدیل متن به گفتار را هم دارد به طوری که می تواند متون مختلف داخل رایانه از جمله متونی که توسط خود نرم افزار نویسا تایپ شده را قرائت کند. وی خاطرنشان کرد: یکی دیگر از قابلیت هایی که به این نرم افزار افزوده شده، تشخیص لهجه و لحن و ایجاد پروفایل شخصی برای تمامی کاربران نرم افزار است. در نسخه جدید نویسا تعدادی صدای پیش فرض ضبط شده که وقتی کاربر تازه ای که صدای او در بخش آموزش صدای نرم افزار وارد نشده با آن کار می کند، نرم افزار با قابلیت تشخیص خودکار گوینده تشخیص می دهد که صدای او به کدام یک از صداهای پیش فرض نزدیک است و خود را با پروفایل آن هماهنگ می کند و در نتیجه نرم افزار در تشخیص گفتار و تایپ صحیح کلمات افزایش می یابد. این قابلیت در کاربردهایی مانند تایپ سخنرانی ها و صحبت هایی که حاوی صدای چند نفر است (مانند مذاکرات صحن علنی مجلس) کارآیی نرم افزار را بسیار افزایش می دهد. وی، امکان کنترل صوتی رایانه و تقویت بخش فرمان های صوتی را از دیگر قابلیت های نسخه جدید عنوان و خاطرنشان کرد: تقریبا تمام کارهای رایانه شامل اجرا و کنترل برنامه های نصب شده در آن می تواند با صوت انجام شود. به این صورت که فرد می تواند با صحبت کردن کارها را انجام دهد، مثلا با گفتن «بزرگ تر» اندازه متن تایپ شده در نرم افزار Word بزرگ تر می شود؛ یا با گفتن «حذف کلمه قبلی» آخرین کلمه قبل از نشان نما پاک می شود.
صدای خود را جایگزین رمز عبور ایمیل و کلید ساختمانها کنید!

در پی دستیابی متخصصان یک شرکت دانشبنیان ایرانی به فنآوری پیشرفته طراحی و ساخت نرمافزار تشخیص گفتار پیوسته فارسی و امکان تایپ مستقیم گفتار توسط رایانه، نسخه جدید این نرمافزار با بانک واژگان دو برابر غنیتر و دقت بسیار بالاتر در تشخیص گفتار و تایپ طراحی شد. دکتر هادی ویسی، مدیر عامل شرکت سازنده این نرمافزار اظهار داشت: نرمافزار تایپ گفتار فارسی که براساس فناوری تشخیص گفتار پیوسته مستقل از گوینده فارسی طراحی شده میتواند گفتار کاربران را که از طریق میکروفن به رایانه منتقل میشود در محیطهای مختلف تایپ کند.برای این کار کافی است که یک میکروفن را به رایانه متصل کرده و متن مورد نظر خود را بخوانید.در این حالت کلام شما به رایانه منتقل شده و نرمافزار آن را پردازش کرده و به متن معادل تبدیل میکند.این نرمافزار همچنین امکان تبدیل فایلهای صوتی ضبط شده به متن را نیز را دارد به طوری که میتوان فایل یک سخنرانی یا مذاکرات یک نشست (با گفتار رسمی) را به نرمافزار دارد و متن تایپ شده آن را تحویل گرفت. وی خاطرنشان کرد: از قابلیتهایی این نرمافزار تشخیص لهجه و لحن و ایجاد پروفایل شخصی برای تمامی کاربران نرمافزار است. ویسی تصریح کرد: مهمترین ویژگی نسخه جدید نرم افزار نویسا که در سه ورژن مختلف عرضه شده کاهش قیمت چشمگیر آن از دو میلیون و 950 هزار تومان و یک میلیون و 400 هزار تومان به 980، 680 و حتی 280 هزار تومان در نسخه خانگی است.همچنین درنسخه جدید نویسا، علاوه برارتقای فنی این نرمافزار از نظر دقت و رفع برخی ازمحدودیتها، بانک واژگان نرمافزار به حدود دوبرابر - تا 120 هزار کلمه - افزایش یافته است.این درحالی است که نسخه قبلی آن 65 هزارکلمه داشت. درنسخ جدید نویسا، بانک کلمات نسخههای تخصصی (پزشکی و حقوقی) به 120 هزارکلمه و برای نسخه عمومی حرفهای به 110 هزار کلمه ارتقا داده شده است. وی خاطرنشان کرد: در نسخههای ابتدایی نویسا در صورت فعال بودن نرمافزار، هر کلامی که از دهان کاربر خارج میشد تایپ میشد؛ مثلاً در مواردی مثل کاربردهای پزشکی، وقتی پزشک مشغول گزارشدهی است و ناگهان شخصی وارد اتاق میشود یا ناگریز از پاسخ دادن به تلفن است در صورت فعال بودن برنامه همه گفتارهای وی تایپ میشد. در نسخه های جدید با ارتقای اینترفیس کاربر و رایانه، فرد میتواند به صورت صوتی فرمان روشن یا خاموش را به نرمافزار بدهد تا فعالیت آن در مواردی که کاربر مایل به ضبط گفتارش نیست قطع شود. ویسی یکی دیگر از قابلیتهای نسخه جدید نرمافزار را امکان ویرایش خودکار متون عنوان و اعلام کرد: عرضه عمومی نسخه جدید نرمافزار ...
روشهای تشخیص هویت بیومتریک (Biometric Methods)
امروزه در امور مربوط به امنیت اماکنی مانند دانشگاه ها، فرودگاه ها، وزارتخانه ها و حتی شبکههای کامپیوتری استفاده از روش های بیومتریک در تشخیص هویت یا تایید هویت افراد بسیار متداول شده است .سیستمهای پیشرفته حضور و غیاب ادارات، سیستمهای محافظتی ورود خروج اماکن خاص، نوتبوکهای مجهز به Finger Print و ... از روشهای مختلف تشخیص هویت بیومتریک استفاده میکنند. در این مقاله سعی میکنیم به صورت مختصر، مروری بر روش¬های مختلف بیومتریک داشته باشیم. مقدمه کلمه Biometric از ترکیب دو کلمه یونانی bios (زندگی) و metrikos (تخمین) شکل گرفته است. بیومتریک عبارت است از، تشخیص هویت افراد با استفاده از ویژگی های فیزیولوژی و رفتاری آنها. این یک تعریف کلی از واژه بیومتریک است. با استناد به این تعریف میتوان گفت که همه افراد در زندگی روزمره خود، ناخودآگاه از بیومتریک استفاده میکنند.به عنوان مثال هویت افرادی که با آنها سرو کار داریم را میتوان از روی صدا، چهره و حتی طرز راه رفتنشان تشخیص دهیم بنابراین میتوان تاریخچه استفاده از بیومتریک را به قدمت تاریخ بشر دانست. سیستم های بیومتریک سیستمهای بیومتریک باید با درصد قابل توجهی قابل اعتماد باشند تا سیستم در تشخیص افراد و اجازه دسترسی آنها اشتباه نکند. در مقایسه با روش های سنتی تشخیص هویت مانند رمز عبور و کارت شناسایی می توان به این مزایای بیومتریک اشاره کرد: • قرض داده نمی شوند. • دزدیده نمی شوند. • گم و یا فراموش نمی شوند • خراب نمی شوند. معمولا یک سیستم بیومتری به کمک الگوریتم های تشخیص الگو (Pattern Recognition) سعی در استخراج ویژگی هایی(features) از رفتار یا ساختار فیزیولوژی فرد می کند و سپس این ویژگی ها را در دیتابیسی ( برای تشخیص و تایید هویت) ذخیره می کند. سیستم هایی که بر اساس علائم فیزیولوژی عمل می کنند بسیار مطمئنتر از سیستم های رفتاری هستند. یک سیستم بیومتریک شامل 4 بخش بنیادی است : • Sensor Module : قسمت نمونه برداری که اطلاعات خام مورد نیاز را جمع آوری می کند. مانند تصویر اثر انگشت. • Feature extraction Module : قسمت پردازش برای استخراج ویژگی ها از اطلاعات مرحله قبل. • Matching Module : قسمت مطابقت که بررسی می کند آیا اطلاعات جمع آوری شده با اطلاعات الگو مطابقت می کند یا خیر؟ مثلا تشخیص می دهد که آیا اطلاعات بدست آمده می تواند متعلق به یک اثر انگشت باشد یا خیر، در صورت مطابقت بر حسب نیاز آن را ذخیره می کند و یا به مرحله بعدی برای تشخیص هویت می رود. • Decision-making Module : قسمتی که اطلاعات ورودی (ویژگی ها) را با اطلاعات ذخیره شده مقایسه می کند و اگر شباهت از درصد معلومی ...