پایگاه داده توزیع شده
پایگاه داده های توزیع شده
پایگاه داده های توزیع شده مقدمه برای طراحی یک سیستم کارا و قابل اعتماد پایگاه داده ی توزیعی تحقیقات و تلاش های بسیاری صورت گرفته است. در اینجا به یکی از جنبه های مهم این تحقیقات یعنی پردازش تراکنشها شامل ارتباط, همروندی, اتمیک بودن, Replication و ترمیم می پردازیم و می کوشیم پیاده سازی این اصول را در سیستمهای مختلف توزیعی تجاری بررسی کنیم. سیستمهای پایگاه های داده ی توزیعی برای برنامه های کاربردی ای هستند که داده ها و دستیابی های به آنها در حالت توزیع شده هستند و نیازمند آن هستیم که در دسترس بودن داده ها را در زمان مواجهه با شکست و خطا حفظ کنیم. یک مثال ساده از از این سیستمها, سیستمهای رزرو بلیط هواپیما و سیستمهای مالی توزیع شده هستند. طراحان پایگاه داده معمولا می کوشند به وسیله ی Replicate و توزیع داده ها آنها را در مقابل های سیستم حفظ کنند. اما Replication باعث ایجاد افزونگی و احتمال بیشتر می شود و نیز مدیریت و پیاده سازی آن بسیار پیچیده است [۱ ]. سیستمهای متعددی هستند که اصول طراحی این سیستمها را رعایت نموده اند: SDD-1 , سیستمهای Ingres توزیع شده, سیستمهای R* و Raid. مسایل و مفاهیم زیادی در طراحی پایگاه های داده ی توزیعی باید مورد توجه قرار گیرد مانند نام گذاری, ارتباطات, کنترل متمرکز و غیرمتمرکز, همروندی, فابلیت اعتماد, replication , اتمیک بودن, و مفاهیم تراکنشها و تراکنشهای تودرتو. همچنین تکنیکهای مختلف توزیع داده ها و بهینه سازی پرس و جوها باید مورد توجه قرار گیرد. در اینجا کوشش می شود نحوه ی استفاده از این تکنیکها و مفاهیم برای طراحی و پیاده سازی یک سیستم پایگاه داده ی مناسب و کارا و نیز یک سیستم مدیریت تراکنش کارا مورد توجه قرار گیرد. بطور خلاصه مفاهیمی را که برای یک پیاده سازی موثر لازم است را مرور می کنیم, مفاهیمی مانند ساختار/معماری سیستم, نرم افزار ارتباطی, همروندی و مدیریت replication در برابر ها است [۱]. ۱- ساختار دو ساختار مختلف برای سیستم ها وجود دارد : سیستمهای برمبنای شیء و سیستمهای Server based . در ساختارهای برمبنای شیء , فرآیندها شیء هارا مدیریت می کنند. مثلا ممکن است یک فرآیند دستیابی همروند به یک شیء را مدیریت می کند و یا امکان را برای آن فراهم می کند, زیرا تراکنشها مسئول این کار نیستند. شیء ها مکانیسمهای مناسبی برای جداسازی داده ها و کپسوله کردن اعمال انجام شده روی آنها می باشند. مثالهایی از سیستمهای برمبنای شیء , سیستمهای Clouds, Eden و Isis هستند. در ساختار های Server based ,فرآیندها برای اعمال مختلف مانند سرور عمل می کنند. بطور مثال یک سرور کنترل همروندی می تواند serializability را برای همه ی تراکنشها فراهم کند. سرور کنترل ...
مقاله پایگاه داده های سیستم های توزیع شده
مقاله پایگاه داده های سیستم های توزیع شده مقاله پایگاه داده های سیستم های توزیع شدهچکیده: پردازش دادههای توزیع شده یک واقعیت تبدیل شده است. دلایلی که هنوز پردازش دادههای توزیع شده را یک موضوع پیچیده میسازد عبارتند از: سیستمهای توزیع شده خیلی وسیع هستند و هزاران سایت متجانس شامل کامپیوترهای شخصی و ماشینهای سرور بزرگ را در بر میگیرد حالت سیستمهای توزیع شده به سرعت تغییر میکند زیرا بارگذاری سایتها از نظر زمانی متنوع میباشد و سایتهای جدید به سیستم افزوده شده است.سیستمهای موجود باید تکمیل گردند. از انجا که سیستمهای موجود برای پردازش توزیعی طراحی نشدهاند و اینک نیاز است که با سیستمهای دیگر در محیط توزیعی تعامل داشته باشند.این مقاله چگونگی انجام پردازش پرسوجو در محیطهای توزیع شده و سیستمهای اطلاعاتی را نمایش میدهد. فهرست: مقدمهتکنیکها و روشهای پایهایی پردازش پرسوجوی توزیعیمعماری پردازش پرسوجوبهینهساز پرسوجوتولید طرح با استفاده از برنامهنویسی پویاتکنیکهای اجرای پرسوجوRow Blockingبهینهسازی برای Multicastاجرای همروند پرسوجوپيوند دادههای پارتیشن شده افقیSemijionDoublePiplined Hash JoinsPointerBased Joins and Distributed Object AssemblyTop N and Bottom N Queriesسیستمهای پایگاه دادهای به صورت CLIENTSERVERمعماریهایCLIENTSERVER، PEERTOPEER و MULTITIERاستفاده از منابع CLIENTانتقال پرسوجوانتقال دادهانتقال ترکیبیمقایسهسیستم پایگاههای داده نامتجانسمعماری WRAPPER برای پایگاههای داده نامتجانستکنیکهای اجرای پرسوجوBindingscursor cachingموقعیتدهی پویای دادهREPLICATION VS CACHINGالگوریتمهای پویای REPLICATIONCACHE INVESTMENTمعماریهای جديد برای پردازش پرسوجومدلهای اقتصادی برای پردازش پرسوجوسيستم اطلاعاتی مبتنی بر انتشار...فرمت فایل: DOC (ورد 2003) قابل ویرایش تعداد صفحات: 24برای دانلود فایل اینجا کلیک کنید
مقاله پایگاه داده های سیستم های توزیع شده
مقاله پایگاه داده های سیستم های توزیع شدهچکیده: پردازش دادههای توزیع شده یک واقعیت تبدیل شده است. دلایلی که هنوز پردازش دادههای توزیع شده را یک موضوع پیچیده میسازد عبارتند از: سیستمهای توزیع شده خیلی وسیع هستند و هزاران سایت متجانس شامل کامپیوترهای شخصی و ماشینهای سرور بزرگ را در بر میگیرد حالت سیستمهای توزیع شده به سرعت تغییر میکند زیرا بارگذاری سایتها از نظر زمانی متنوع میباشد و سایتهای جدید به سیستم افزوده شده است.سیستمهای موجود باید تکمیل گردند. از انجا که سیستمهای موجود برای پردازش توزیعی طراحی نشدهاند و اینک نیاز است که با سیستمهای دیگر در محیط توزیعی تعامل داشته باشند.این مقاله چگونگی انجام پردازش پرسوجو در محیطهای توزیع شده و سیستمهای اطلاعاتی را نمایش میدهد. فهرست: مقدمهتکنیکها و روشهای پایهایی پردازش پرسوجوی توزیعیمعماری پردازش پرسوجوبهینهساز پرسوجوتولید طرح با استفاده از برنامهنویسی پویاتکنیکهای اجرای پرسوجوRow Blockingبهینهسازی برای Multicastاجرای همروند پرسوجوپيوند دادههای پارتیشن شده افقیSemijionDoublePiplined Hash JoinsPointerBased Joins and Distributed Object AssemblyTop N and Bottom N Queriesسیستمهای پایگاه دادهای به صورت CLIENTSERVERمعماریهایCLIENTSERVER، PEERTOPEER و MULTITIERاستفاده از منابع CLIENTانتقال پرسوجوانتقال دادهانتقال ترکیبیمقایسهسیستم پایگاههای داده نامتجانسمعماری WRAPPER برای پایگاههای داده نامتجانستکنیکهای اجرای پرسوجوBindingscursor cachingموقعیتدهی پویای دادهREPLICATION VS CACHINGالگوریتمهای پویای REPLICATIONCACHE INVESTMENTمعماریهای جديد برای پردازش پرسوجومدلهای اقتصادی برای پردازش پرسوجوسيستم اطلاعاتی مبتنی بر انتشار...فرمت فایل: DOC (ورد 2003) قابل ویرایش تعداد صفحات: 24برای دانلود فایل اینجا کلیک کنید
معماری پایگاه داده ها
معماری پایگاه داده ها به چند دسته مختلف تقسیم می شوند · [1] سیستم های متمرکز · [2] سیستم های مشتری/خدمتگزار · [3] سیستم های موازی · [4] سیستم های توزیع شده در ادامه به شرح سیستم های مختلف می پردازیم. 1. سیستمهای متمرکز [Silb] در این نوع سیستم ها تمامی اطلاعات در یک پایگاه ذخیره و همچنین بازیابی می شوند بدین ترتیب که کاربران برای استفاده از اطلاعات ذخیره شده فقط باید به دستگاهی که پایگاه در آن ذخیره شده است مراجعه کنند. اینگونه پایگاه داده ها که امروزه کمتر مورد استفاده قرار می گیرند، برای استفاده در مواردی که کاربرد زیادی دارند ایجاد می شوند. همانطور که در شکل مشاهده می شود، در این نوع معماری پایگاه داده در یک کامپیوترقرار دارد. بدین معنی که در این معماری یک یا بیشتر پردازنده و یک حافظه مشترک بین پایگاه داده و سیستم عمل وجود دارد. از مزایای این نوع معماری می توان موارد ریز را برشمرد: · سادگی در طراحی . سادگی در استفاده · عدم نیاز به امکانات سخت افزاری یا نرم افزاری خاص همچنین از معایب آن می توان به موارد زیر اشاره کرد: · تک کاربره بودن · مشکل بودن استفاده در سازمانهای بزرگ با توجه به گسترش روز افزون استفاده از پایگاه داده ها و همچنین بیشتر شدن حجم اطلاعات و تعداد کاربران سیستم های متمرکز به تدریج جای خود را به معماری هایی با قابلیت های بیشتر برای استفاده گسترده تر دادند. 2. سیستم های مشتری/خدمتگزار [Silb] این نوع معماری بعد از معماری متمرکز و به علت نا کارآمدی معماری متمرکز در سیتم های بزرگتر بوجود آمد. در این نوع معماری قسمت های مختلف پایگاه داده در کامپیوتر های مختلف قرار می گیرند. در این روش یک کامپیوتر نقش سرور را به عهده می گیرند و کاربران می توانند با استفاده از کامپیوتر های دیگر و متصل شدن به سرور از پایگاه داده استفاده کنند. همانطور که مشخص است کاربران و کامپیوترها برای اتصال به سرور نیازمند به شبکه کامپیوتری هستند پس در واقع شبکه های کامپیوتری یکی از ملزومات این نوع معماری به حساب می آید. بخش های مختلف پایگاه داده ها در این نوع معماری بر حسب کاربری به دو بخش تقسیم می شود: · Back-end : این قسمت وظیفه بررسی و کنترل دسترسی ها، بررسی و بهینه سازی پرس و جو[5] ها و کنترل همزمانی ها و سالم بودن پایگاه داده ها را به عهده دارد. · Front-end: شامل ابزار هایی برای نمایش و زیباسازی نتایج پرس و جو ها مثل ابزارهای تولید فرم ها و ابزار های گزارش گیری می باشد. برای ایجاد ارتباط درست میان دو قسمت فوق نیازمند ...
پیاده سازی پايگاه داده توزيع شده توسط Microsoft SQL Server
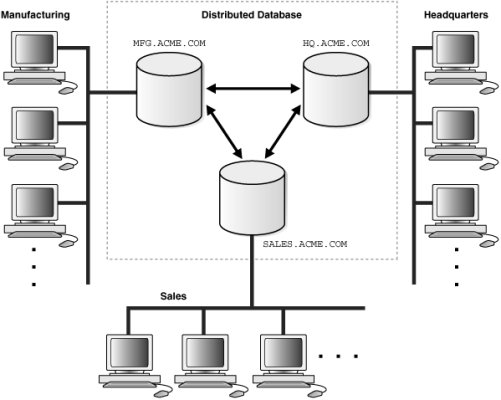
پیاده سازی پايگاه داده توزيع شده توسط Microsoft SQL Serverتالیف: مرتضی سرگلزایی جوانPDF | 12 Pages | 700 KB | FA | لينک مستقيم با قابليت رزوم - فهرست مباحث کتاب:مقدمهسيستم توزيع شدهپايگاه اطلاعات توزيع شدهمزاياي سيستم پايگاهي توزيع شدهمعايب سيستم پايگاهي توزيع شدهذخيره اطلاعات به صورت توزيع شدهمحاسن روش Replication معايب روش Replication پياده سازي بانك اطلاعات توزيع شده در SQL Server 2005تابع OPENdatasource()سرورهاي متصل (Linked Server)تراكنش هاي توزيع شدهلینک دانلود کتاب : Downloadکلمه عبور: www.farsibooks.irبعد از کليک بر روي لينک دانلود وارد صفحه اي ميشويد که بعد از چند ثانيه بهتون لينک مستقيم ميده که ميتونيد اين لينک رو وارد دانلود منجر کنيد ...
مقاله پایگاه داده های سیستم های توزیع شده
مقاله پایگاه داده های سیستم های توزیع شدهچکیده: پردازش دادههای توزیع شده یک واقعیت تبدیل شده است. دلایلی که هنوز پردازش دادههای توزیع شده را یک موضوع پیچیده میسازد عبارتند از: سیستمهای توزیع شده خیلی وسیع هستند و هزاران سایت متجانس شامل کامپیوترهای شخصی و ماشینهای سرور بزرگ را در بر میگیرد حالت سیستمهای توزیع شده به سرعت تغییر میکند زیرا بارگذاری سایتها از نظر زمانی متنوع میباشد و سایتهای جدید به سیستم افزوده شده است.سیستمهای موجود باید تکمیل گردند. از انجا که سیستمهای موجود برای پردازش توزیعی طراحی نشدهاند و اینک نیاز است که با سیستمهای دیگر در محیط توزیعی تعامل داشته باشند.این مقاله چگونگی انجام پردازش پرسوجو در محیطهای توزیع شده و سیستمهای اطلاعاتی را نمایش میدهد. فهرست: مقدمهتکنیکها و روشهای پایهایی پردازش پرسوجوی توزیعیمعماری پردازش پرسوجوبهینهساز پرسوجوتولید طرح با استفاده از برنامهنویسی پویاتکنیکهای اجرای پرسوجوRow Blockingبهینهسازی برای Multicastاجرای همروند پرسوجوپيوند دادههای پارتیشن شده افقیSemijionDoublePiplined Hash JoinsPointerBased Joins and Distributed Object AssemblyTop N and Bottom N Queriesسیستمهای پایگاه دادهای به صورت CLIENTSERVERمعماریهایCLIENTSERVER، PEERTOPEER و MULTITIERاستفاده از منابع CLIENTانتقال پرسوجوانتقال دادهانتقال ترکیبیمقایسهسیستم پایگاههای داده نامتجانسمعماری WRAPPER برای پایگاههای داده نامتجانستکنیکهای اجرای پرسوجوBindingscursor cachingموقعیتدهی پویای دادهREPLICATION VS CACHINGالگوریتمهای پویای REPLICATIONCACHE INVESTMENTمعماریهای جديد برای پردازش پرسوجومدلهای اقتصادی برای پردازش پرسوجوسيستم اطلاعاتی مبتنی بر انتشار...فرمت فایل: DOC (ورد 2003) قابل ویرایش تعداد صفحات: 24برای دانلود فایل اینجا کلیک کنید