سیگنال
۱- اهمیت مدلسازی سیگنال
تشخیص کامپیوتری صحبت در واقع بر دارندهی دو نوع عمل اصلی تشخیص است: تشخیص صحبت و تشخیص گوینده. با تحلیل یک موج صوتی میتوان خصیصههای۱ اندامهای گفتاری گوینده را تخمین زد که این خصیصهها راهکاری برای تشخیص هویت و تصدیق آن به روش زیستسنجی فراهم میآورند. در مقابل، سیستمهای تشخیص صحبت برای درک مفهوم موج صوتی گفته شده تلاش میکنند. جهت بیشتر تحقیقات فعلی در فنآوری تشخیص صحبت به سمت ایجاد سیستمهای مستقل از گوینده است که توانایی تبدیل صحبت همهی گویندگان را داشته باشد. در حالی که اهداف این دو نوع سیستم کاملاً متفاوت به نظر میرسند هر دو عمیقاً از آبشخوری به نام الگوریتمهای پردازش سیگنال برای استخراج خصیصهها۲ تغذیه میشوند. در هر دو زمینه تلاش برای پیدا کردن دستهای از خصیصهها که در مقابل تغییرات محیطی پایدار باشند ادامه دارد. این قسمت مروری خواهد داشت بر الگوریتمهای استخراج خصیصهها که در هر دو زمینه استفاده شدهاند و شامل ارزیابی کوتاهی از الگوریتمهای گوناگون مدلسازی سیگنال با آزمایشهای تشخیصی کوچک میباشد.
۲- آشنایی با مدلسازی سیگنال
هدف سیستمهای تشخیص گوینده بازشناسی خصیصههای اندامهای گفتاری و حالت صحبت کردن با استفاده از صدای گوینده به منظور اهداف تشخیص هویتی میباشد. ساختار اندامهای صوتی، اندازهی چالهی بینی و ویژگیهای تارهای صوتی همگی با استفاده از تحلیل سیگنال قابل تخمین هستند. تشخیص گوینده اصطلاحی کلی است که به اعمال تشخیص هویت گوینده و تأیید هویت گوینده اطلاق میگردد. برای تشخیص، خصیصههای تخمینی گوینده با خصیصههای موجود در یک پایگاه دادهها از کاربران ثبت شده برای یافتن نزدیکترین خصیصههای قابل تطبیق مقایسه میشوند. برای تأیید هویت، ادعای هویتی گوینده بر اساس امضای زیستسنجی وی پذیرفته میشود و یا رد میگردد.
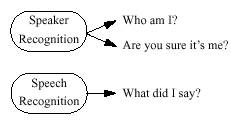
شکل شماره ۱ – وظایف مختلف
تشخیص صحبت تلاش دارد تا یک سیگنال صوتی صحبت را به واژهها تبدیل کند. انسانها واژهها را با حرکت دادن اندامهای صوتی به یک سری از مکانهای قابل پیشبینی ادا میکنند. اگر این دنبالهها از سیگنال استخراج گردند واژههای گفته شده میتوانند تشخیص داده شوند. بسیاری از کاربردهای تشخیص صحبت نیازمند سیستمهای مستقل از گوینده میباشند این تولیدات میتوانند صحبت هر گویندهای را تشخیص دهند.
اگر چه این دو هدف کاملاً متفاوت به نظر میرسند هر دوی آنها بر روی دادههای صحبت تشخیص الگو را اعمال میکنند. بعضی از سیستمهای موجود مانند Nuance ۶ server هم تشخیص صحبت و هم تأیید هویت گوینده را به صورت همزمان اعمال میکنند. به خاطر همین شباهت رویه هر دوی این فنآوریها از یک نقطه ضربه میخورند: یک تنزل کارایی شدید در اثر تفاوتهای محیطهای آموزشی و آزمایشی به وجود میآید. به طور خلاصه کارایی این فنآوریها شدیداً به محیطی که در آن توسعه مییابند وابسته است و بنابراین حالات پر از نویز جهان واقعی آنها را به کارایی زیر کارایی بهینه راهبری میکند.
الگوریتمهایی مورد استفادهی محصولات پردازش کنندهی صحبت بر اساس مدل صوتی ناحیهی صوتی و کانال گوش استوارند. بخش بعدی اهمیت استخراج خصیصهها را با یک مرور کلی از تشخیص الگو روشن میکند و سپس با توصیف الگوریتمهای رایج در محصولات پراستفاده ادامه پیدا میکند.
۳- تشخیص الگو
یک سیستم تشخیص الگو شامل دو جزء است: یک استخراج کنندهی خصیصهها و یک طبقهبندی کننده. ایدهآل آن است که وقتی دادهها به فضای دادههای خصیصهها انتقال پیدا کرد به سمت طبقهای کشیده شود که از همه به آن نزدیکتر است و از طرف طبقههای۳ متفاوت دیگر بازپس زده شود. وقتی که به طبقهبندی کننده۴ آموزش داده شد که بین طبقهها در این فضای انتقال داده شده از خصیصهها تمایز قائل شود یک سیستم تشخیص نیازمند آن است که تنها دادههای ورودی را از طریق همان سیستم استخراج خصیصهها انتقال دهد و مشخص کند که در کدام طبقه یک مشاهدهی جدید رخ میدهد.
دو مشکل مهم در اعمال این راهکار به پردازش صحبت وجود دارد. اولی آن است که هیچ التزامی وجود ندارد که محیط آموزش و محیط آزمایش قابل مقایسه باشند. استفاده از یک میکروفون متفاوت، نویز پسزمینه و کانالهای انتقال میتواند باعث کاهش کارایی جدی شود (یک معیار اساسی برای قضاوت در مورد یک مجموعه از خصیصهها پایداری آن در مقابل چنین تغییرات کانالی میباشد) . دومین مشکل آن است که که برهمنهی زیادی بین طبقههای موجود در فضای خصیصهها وجود دارد. ژائو۵ نمودارهایی برای نشان دادن این برهمنهی در دو دسته دادههای صحبت جمعآوری شده از طریق شبکهی تلفن ارائه میکند. موتورهای تشخیص صحبت برای غلبه بر این مشکل برهمنهی از پردازشهای آماری توانمند برای یکسانسازی مدل زبان استفاده میکنند که فراتر از حد این نوشتار است.
۴- الگوریتمهای مدلسازی سیگنال
هدف مدلسازی سیگنال (که اغلب از آن با عنوان استخراج خصیصهها یاد میشود) انتقال دادههای صوتی به فضایی است که مشاهدات مربوط به یک طبقه با هم در یک گروه قرار گیرند و مشاهدات مربوط به طبقات متفاوت از هم جدا شوند. این انتقالها بر اساس مطالعات زیستشناختی سیستمهای صوتی و اندامهای گفتاری انسان انتخاب میشوند. برای مثال اندامهای گفتاری نمیتوانند از یک مکان به مکان دیگر در کمتر از حدود پنج میلیثانیه جابهجا شوند لذا سیستمهای عملی میتوانند از طیف ۱۰۰ بار در ثانیه نمونهبرداری کنند در حالی که از دقت عملیات فقط مقدار بسیار کمی کاسته شود.
صحبت یک سیگنال پویاست لذا ما علاقمند به آزمون طیف بازهی کوچک هستیم. زمان استمرار یک قاب به صورت طول زمانی که یک مجموعه از پارامترها معتبر هستند تعریف میشوند. با وجود این که قابها همپوشانی ندارند ما معمولاً از پنجرهی تحلیل دارای همپوشانی برای در نظر داشتن تعداد بیشتری از نمونههای سیگنال برای هر اندازهگیری طیف استفاده میکنیم. اعمال مستقیم تحلیل طیفی بر روی چنین مقدار کمی از دادهها معادل با اعمال یک پنجرهی مستطیلی تیز به سیگنال است که باعث ایجاد اعوجاج طیفی میشود. پاسخ فرکانسی پالس مستطیلی یک تابع sinc میباشد( (sinc x=sin x/x که دارای یک باند عبور منحنی شکل و مقدار زیادی ناهمواری در باند توقف میباشد. شکلهای مختلف برای پنجرهها از طریق اعمال یک تابع وزن به دست میآیند. پنجرهی همینگ۶ با رابطهی
w(n)= (a-(۱-a)cos(۲p/[N-۱])/ b
یک نمونهی ویژه از پنجرهی هنینگ۷ با=۰.۵۴ a میباشد (p عدد پی (… ۳.۱۴۱۵) است). پارامتر b برای هنجارسازی به گونهای انتخاب میشود که انرژی سیگنال در خلال آزمایش بدون تغییر باقی بماند. شکل پنجرهی همینگ یک تحلیل طیفی با باند عبور هموارتر و باند توقف به طور قابل ملاحظهای بدون اعوجاج به دست میدهد که هر دوی این خصوصیات برای به دست آوردن تخمینهای پارامتری متغیر مهم هستند. بیشتر سیستمهای امروزی از یک از یک فریم با اندازهی زمانی ۱۰ میلیثانیه و یک پنجره با اندازهی زمانی ۲۵ میلیثانیه استفاده میکنند.
یک خصیصهی استخراج شده از سیگنال انرژی مطلق سیگنال است. دستهی دیگر، اندازهگیری طیفی انرژی فرکانسهای خاص است. این اندازهها مشابه حالات اولیهی حرکات دستگاه صوتی انسان هستند (سلولهای مو در حلزون گوش برای دستیابی به هدف مشابهی استفاده میشوند). سه راه برای دستیابی به این اندازههای صوتی وجود دارد: اعمال مستقیم یک بانک فیلتر دیجیتال در دامنهی زمان، استفاده از تبدیل فوریه و تحلیل پیشگویانهی خطی. دو روش اخیر به لحاظ کارایی محاسباتی در سیستمهای امروزی رایجترند.
از آنجا که شنوایی انسان در طول یک اندازهی خطی به صورت مساوی حساس نیست، ما طیف را به یک اندازهی فرکانسی قابل درک۸ نقش میکنیم. تجربیات در مورد ادراک انسان نشان دادهاند که فرکانسهایی با یک پهنای باند معینِ یک فرکانس اسمی که به پهنای باند بحرانی معروف است نمیتوانند به صورت جداگانه از هم تشخیص داده شوند. اندازهی مل۹ یک تقریب سادهتر است که پیچ قابل مشاهدهی یک صدا را به اندازهی خطی نقش میکند. استیونز۱۰ و فولکمن۱۱ در سال ۱۹۴۰ به صورت تجربی نگاشتی بین اندازهی مل و فرکانسهای واقعی تعیین کردند. تفاوت اندازه به سختی به صورت خطی زیر ۱۰۰۰هرتز و به صورت لگاریتمی بالای ۱۰۰۰هرتز میباشد.

شکل شماره ۲- بانکهای فیلتر با فضای مثلثی مل
بانکهای فیلتر مبتنی بر تبدیل فوریهی ساده که برای خصیصههای نهایی طراحی شدهاند دقت فرکانسی دلخواه را بر اساس مقیاس مل۱۲ به دست میدهند. برای پیادهسازی این بانک فیلتر پنجرهی دادههای صحبت با استفاده از تبدیل فوریه به دامنهی فرکانس انتقال مییابد. در دامنهی فرکانس ضرایب دامنهی هر بانک فیلتر با اعمال یک ترکیب خطی از طیف و پاسخ فرکانسی فیلتر دلخواه پیدا میشوند. در عمل بانکهای فیلتر مثلثی دارای برهمنهی استفاده میشوند که در آن از فرکانس مرکزی یک فیلتر به عنوان نقاط انتهایی دو فیلتر مجاور استفاده میشود. بنابراین ضرایب دامنهی هر بانک فیلتر مقدار متوسط طیف در کانال فیلتر را نشان میدهند:

که در آن N(s) تعداد نمونههای استفاده شده برای دستیابی به مقدار متوسط و W(n) تابع وزنیابی (مشابه تابع مثلثی که قبلاً توضیح داده شد) میباشد و S(f) مقدار پاسخ فرکانسی است که با تبدیل فوریه محاسبه میشود.
تحلیل پیشگویانه خطی۱۳ وسیلهای برای به دست آوردن پوشش طیفی هموار P(w) از یک مدل تمام- قطب طیف توان است. ضرایب خطی پیشگو همبستگی مستقیمی با نسبتهای ناحیهی لگاریتمی که پارامترهای هندسی مدل لولهای نقصان برای تولید صحبت هستند دارد. دامنههای بانک فیلتر با نمونهبرداری از مدل طیفی پیشگویانهی خطی در فرکانسهای بانک فیلتر مناسب به دست میآیند. این کار میتواند با ارزیابی مستقیم مدل ال.پی.سی انجام شود ولی در عمل تبدیل فوریه بر روی ضرایب پیشگو اعمال میشود. چون تعداد ضرایب ال.پی.سی کمتر از نمونههای صوت است این روش از لحاظ محاسباتی کاراست. ضرایب دامنهی بانک فیلتر همان گونه که از طیف حاصل از تبدیل فوریه۱۴ به دست میآمدند از طیف حاصل از پیشگویانهی خطی۱۵ به دست میآیند.
یک سیستم همریخت۱۶ برای پردازش صحبت قابل استفاده است زیرا روشی برای جدا کردن سیگنال آشفتگی از شکل ناحیهی صوتی فراهم میآورد. یک فضای دارای این ویژگی سپستروم۱۷ است که با محاسبهی عکس تبدیل فوریهی گسستهی لگاریتم انرژی به دست میآید.ضرایب سپسترال با محاسبهی دامنههای بانک فیلتر با استفاده از معادلهی زیر به دست میآیند:

که S(avg) مقدار متوسط سیگنال در کانال kام فیلتر است. در عمل تبدیل کسینوسی گسسته به خاطر کارایی محاسباتی استفاده میشود. ضرایب سپسترال اغلب برای کمینه کردن تغییراتی که منجر به ایجاد اطلاعات نمیشوند وزنیابی میگردند که این پردازه لیفترینگ۱۸ نامیده میشود. جالب است بدانیم که در ادبیات تشخیص صحبت خصیصههای مربوط به گوینده به عنوان تغییرات غیر دادهزا حذف میگردند ولی سیستمهای تشخیص گوینده نیز از لیفترینگ استفاده میکنند.
هر دو نوع سیستم تشخیص صحبت و تشخیص گوینده اطلاعات موضعی زمان کوتاه را با گرفتن مشتق خصوصیات اولیه نسبت به زمان به دست میدهند. به عنوان مثال یک صوت صدادار میتواند با پیدا شدن فرمانتهای۱۹ آن در طیف تشخیص داده شود، حال آن که یک صوت بیصدا (سایشی) با استفاده از انتقال طیف مدل میشود. مقادیر مشتق مرتبهی اول خصائص ضرایب دلتا۲۰ و مقادیر مشتق مرتبهی دوم آن شتاب۲۱ یا ضرایب دلتا-دلتا۲۲ نامیده میشوند.مشتق زمانی با استفاده از یک رابطهی رگرسیون که یک مجموعه فریم را پیش و پس از فریم کنونی میکشد تقریب زده میشود.
سیستمهای تشخیص گوینده از یک پیمانهی انتخاب خصیصه نیز در چارچوب تشخیص الگو استفاده میکنند. برای تشخیص صحبت تمامی سیگنال باید به یک نمایش متنی نگاشته شود حال آن که سیستم تشخیص گوینده نیازی به کار تحت این اجبار ندارد. بنابراین پیمانهی انتخاب خصیصه فقط خصیصهها مربوط به اصوات صدادار را ذخیره میکند. اصوات صدادار مستقیماً فرضیات مدلسازی پیشگویانهی خطی را برآورده میسازند و کمتر تحت تأثیر نویز صوتی قرار میگیرند.
۵- منابع
1) Richard Duncan, Mississippi State University, A Description And Comparison Of The Feature Sets Used In Speech Processing
*feature
*feature extraction
*class
*classifier
*Zhao
*Hamming window
*Hanning window
*perceptual
*mel scale
*Stevens
*Volkman
*Mel frequency
*Linear Predictive [LP] anlaysis
*FT-deriven spectrum
*LP-deriven spectrum
*homomorphic
*cepstrum
*liftering
*formants
*delta coefficients
*acceleration
*delta-delta coefficients
مطالب مشابه :
1507. بررسی و ارزیابی چند روش تشخیص جنسیت گوینده از روی گفتار
گروه فني مهندسي شکیبا - 1507. بررسی و ارزیابی چند روش تشخیص جنسیت گوینده از روی گفتار - شبیه
ترجمه مقاله تعیین هویت گوینده مستقل از متن، توسط مدل های مخلوط گاوس
تحقیقات بر روی تشخیص گوینده که شامل تعیین هویت و تطبیق موارد می باشد به عنوان یک مورد فعال
دانلود کد تشخیص گوینده در متلب
برنامه Open source تشخیص گوینده در نرم افزار متلب : برای دانلود کلیک کنید اعمال جبر در سمبلیک
سیگنال
سیستمهای تشخیص گوینده از یک پیمانهی انتخاب خصیصه نیز در چارچوب تشخیص الگو استفاده میکنند.
مروری بر سیستم تشخیص گفتار و کاربرد آن
عصر پیشرفت - مروری بر سیستم تشخیص گفتار و کاربرد آن - وبگاه علمی پژوهشی
نرمافزار تشخیص گفتار فارسی به بازار میآید
نرمافزار تشخیص به تغییرات موجود در شرایط آکوستیکی محیط و تغییرات موجود بین گوینده
لب خوانی چیست؟
مشاهده گوینده نه تنها درک گفتار شنیده تفاوت معنا داری بین درصد تشخیص واج ها مورد آزمایش
نرم افزار تایپ گفتار فارسی طراحی شد
رایانه ، نسخه جدید این نرم افزار با قابلیت های قرائت متون مختلف و تشخیص خودکار گوینده
صدای خود را جایگزین رمز عبور ایمیل و کلید ساختمانها کنید!
نرمافزار تایپ گفتار فارسی که براساس فناوری تشخیص گفتار پیوسته مستقل از گوینده فارسی
روشهای تشخیص هویت بیومتریک (Biometric Methods)
مغزهای حقوق - روشهای تشخیص هویت بیومتریک رفتاری است و در تشخیص گوینده به ما کمک می کند؟
برچسب :
تشخیص گوینده