محاسبه رگرسیون توبیت (Tobit Regression) در Stata
مدل های توبیت که گاها رگرسیون حساس شده و یا سانسور شده نامیده می شوند، به منظور بررسی روابط خطی در شرایطی که در مورد متغیر وابسته یک حد بحرانی در سمت راست یا چپ مشاهده شود استفاده می شود. از این رو به این نوع خاص از توابع پیش بینی رگرسیون سانسور شده نیز اطلاق می شود. وجود موارد فراتر از حد بحرانی یا پائین تر از حد بحرانی در متغیر وابسته بیانگر یک مشکل جدی و اریب در معادله رگرسیون است و نیازمند استفاده از رگرسیون توبیت است. به دیگر سخن وجود این سطح از پراکنش سبب خطای جدی در شرایط استفاده از رگرسیون خطی می شود. به عنوان مثال در نظر بگیرید محققی علاقه مند است متغیر های پیش بینی کننده سطح سرب آب آشامیدنی که وجود مقادیر بالای 15 ppb آن خطر ناک است را مطالعه کند به این منظور سن ساختمان مسکونی و وضعیت معیشتی را به عنوان متغیر های پیش بینی کننده مورد توجه قرار داد. یک مشکلی که در این رابطه وجود دارد این است که دستگاه تشخیص سرب مقادیر زیر 5 ppb را تشخیص نمی دهد و مقدار صفر را نشان می دهد در حالیکه این مقدار صفر واقعی نیست. لذا این برآورد در رگرسیون خطی اشتباه خواهد بود.
به منظور مطالعه این روش در نرم افزار STATA یک مثال عملی مورد توجه قرار می گیرد. در نظر بگیرید در یک آزمون نظر سنجی یک برنامه تبلیغاتی کاربران به این برنامه از 0 تا 10 در قالب ایتم های مختلف نمره می دهند. حداقل نمره 200 و ماکزیمم آن 800 می باشد. افرادی که تمام آیتم ها را مثبت ارزیابی کرده باشند 800 را به برنامه داده اند و اگر تمام ایتم ها را منفی ارزیابی کنند 200 را به برنامه تبلیغاتی داده اند. لیکن افرادی که 800 می گیرند یا 200 الزاما همگی مانند هم نیستند. در این تحقیق 200 نفر مشارکت کردند که متغیر وابسته نمره ارزیابی یا ase و متغیر های مستقل شامل دو متغیر میزان تمایل به خرید و میزان تمایل به محصولات آن برند است. دستور زیر را به منظور کسب وضعیت توصیفی داده ها به کار می بریم.
summarize ase purc bran
Variable | Obs Mean Std. Dev. Min Max
-------------+--------------------------------------------------------
ase | 200 640.035 99.21903 352 800
purc | 200 52.23 10.25294 28 76
bran | 200 52.645 9.368448 33 75
برای مشاهده فرم توزیع نیز از دستور زیر برای متغیر وابسته استفاده می کنیم.
(histogram ase, normal bin(10) xline(800
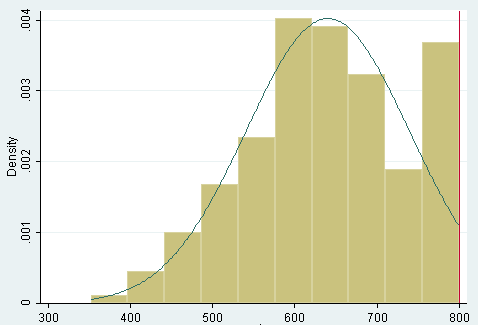
نتایج حاصله نشان می دهد که نمرات بین 750 تا 800 غالب داده های متغیر وابسته را نشان می دهند. با استفاده از دستور زیر این موضوع بهتر نمایان می شود. نتایج نشان می دهد که غالب این دیتا دارای یک اریب معنی دار است.
histogram ase, discrete freq

برای دیدن روابط همبستگی نیز دستور زیر را باید وارد کرد. که نتایج وجود همبستگی متوسط به بالایی را در بین متغیر های تحقیق نشان می دهند. زیرا ضرایب فراتر از 5/0 محاسبه شده اند.
correlate ase purc bran
(obs=200)
| ase purc bran
-------------+---------------------------
ase | 1.0000
purc | 0.6623 1.0000
bran | 0.6451 0.7333 1.0000
این روابط همبستگی توسط دستور زیر قابل مشاهده است.
graph matrix ase purc bran, half jitter(2)
نتایج اسکترپلات نیز بیانگر وجود رابطه خطی قدرتمند بین متغیر های مستقل و وابسته است. با توجه به این ضرایب قابلیت به کارگیری مدل های رگرسیونی وجود دارد. لذا با توجه به اریب موجود باید از رگرسیون توبیت استفاده کرد. به کارگیری رگرسیون OLS سبب ایجاد نا همگنی ضریب متغیر های مستقل می شود که به طور تصادفی بر روی این قسمت از داده ها برازش د ارند. در حالیکه تعداد 800 به عنوان حد بحرانی است. به منظور محاسبه این نوع از رگرسیون می توان دستور زیرا را وارد کرد. حد بحرانی را باید بعد از المان ul قرار داد.
tobit ase purc bran i.prog, ul(800)

مقدار log likelihood بیانگر مناسب بودن توزیع و برازش تابع رگرسیونی است. در بالای خروجی مشخص می شود که 200 مورد در تحقیق مشارکت داشته اند و داده های انها قابل قبول است. مقدار کای اسکویر دارای سطح معنی دار بوده و نشان می دهد حداقل یک متغیر مستقل برای پیش بینی در مدل موجود بوده و مدل پیشنهادی بهتر از مدل خالی از متغیر مستقل عمل می کند. مقادیر سطح معنی داری زیر 05/0 است لذا هر دو متغیر مستقل دارای اثر پیش بینی کننده است. نتایج نشان می دهد با یک واحد افزایش در میزان تمایل به خرید نمره فرد تا 7/2 برابر افزایش می یابد. و با یک واحد افزایش در میزان تمایل به محصولات آن برند 90/5 واحد در نمره ارزیابی فرد تاثیر دارد. به دیگر سخن نتایج نشان می دهد افراد در ارزیابی خود از پیام تبلیغاتی میزان تمایل به محصولات آن برند، و میزان تمایل به خرید تاثیر می پذیرند. در صورت نیاز به کسب اطلاعات بیشتر می توان به منبع زیر مراجعه نمود.
Long, J. S. and Freese, J. 2006. Regression Models for Categorical and Limited Dependent Variables Using Stata. 2nd ed. College Station, TX: STATA Press.
مطالب مشابه :
محاسبه رگرسیون خطی-آمار توصیفی بدون نیاز به نرم افزار
آمار - محاسبه رگرسیون خطی-آمار توصیفی بدون نیاز به نرم افزار - همه چيز براي آماريها: کتاب، حل
آموزش نحوه محاسبه مدل رگرسیون لجستیک Binomial logistic regression در نرمافزار SPSS
آمار برای همه - آموزش نحوه محاسبه مدل رگرسیون لجستیک Binomial logistic regression در نرمافزار SPSS - آمار
محاسبه رگرسیون توبیت (Tobit Regression) در Stata
یادداشت های اقتصادی - محاسبه رگرسیون توبیت (Tobit Regression) در Stata - علی رئوفی/ دانشجوی دکترای
محاسبه رگرسیون خطی
بچه های زیست شناسی دانشگاه محقق اردبیل - محاسبه رگرسیون خطی - گزارش کار و مقاله - بچه های زیست
کاربرد آنالیز رگرسیون خطی(Linear Regression) با استفاده از نرم افزار SAS
با توجه به سوالات مکرر دانشجویان در مورد نحوه محاسبه رگرسیون خطی در نرم افزار sasبر آن شدم تا
آموزش مقدماتی رگرسیون با نرم افزار اکسل
آمار؛کلید توسعه - آموزش مقدماتی رگرسیون با نرم افزار اکسل - برنامه ریزی بدون آمار ، تیری است
تحلیل رگرسیون و رگرسیون کاذب
» معرفی گروه و خدمات آن: ( دوشنبه ۳ تیر۱۳۹۲ ) » ـ فرمول محاسبه حجم نمونه در مطالعات مشاهده ای
آموزش رگرسیون چند متغیره در spss
محــاسبه, آماره, آماره t در ادامه یک فایل آموزش تصویری رگرسیون چند متغیره در نرم افزار
رگرسیون در علوم دامی
math.statistic.genetic - رگرسیون در علوم دامی - ریاضی آمار کامپیوتر ژنتیک
برچسب :
محاسبه رگرسیون